To a spider,
www.domain.com/, domain.com/, www.domain.com/index.html and domain.com/index.html are different urls and, therefore, different pages. Surfers arrive at the site's home page whichever of the urls are used, but spiders see them as individual urls, and it makes a difference when working out the PageRank. It is better to standardize the url you use for the site's home page. Otherwise each url can end up with a different PageRank, whereas all of it should have gone to just one url.
If you think about it, how can a spider know the filename of the page that it gets back when requesting
www.domain.com/ ? It can't. The filename could be index.html, index.htm, index.php, default.html, etc. The spider doesn't know. If you link to index.html within the site, the spider could compare the 2 pages but that seems unlikely. So they are 2 urls and each receives PageRank from inbound links. Standardizing the home page's url ensures that the Pagerank it is due isn't shared with ghost urls.
Example: Go to
UK Holidays and UK Holiday Accommodation site - how's that for a nice piece of link text ;). Notice that the url in the browser's address bar contains "www.". If you have the Google Toolbar installed, you will see that the page has PR5. Now remove the "www." part of the url and get the page again. This time it has PR1, and yet they are the same page. Actually, the PageRank is for the unseen frameset page.
When this article was first written, the non-www URL had PR4 due to using different versions of the link URLs within the site. It had the effect of sharing the page's PageRank between the 2 pages (the 2 versions) and, therefore, between the 2 sites. That's not the best way to do it. Since then, I've tidied up the internal linkages and got the non-www version down to PR1 so that the PageRank within the site mostly stays in the "www." version, but there must be a site somewhere that links to it without the "www." that's causing the PR1.
Imagine the page, www.domain.com/index.html. The index page contains links to several relative urls; e.g. products.html and details.html. The spider sees those urls as www.domain.com/products.html and www.domain.com/details.html. Now let's add an absolute url for another page, only this time we'll leave out the "www." part - domain.com/anotherpage.html. This page links back to the index.html page, so the spider sees the index pages as domain.com/index.html. Although it's the same index page as the first one, to a spider, it is a different page because it's on a different domain. Now look what happens. Each of the relative urls on the index page is also different because it belongs to the domain.com/ domain. Consequently, the link stucture is wasting a site's potential PageRank by spreading it between ghost pages.

Saturday, August 05, 2006
How much PageRank do we need to move up?
Here's the details. Why the values shown in the Google toolbar are not the actual PageRank figures. According to the equation, and to the creators of Google, the billions of pages on the web average out to a PageRank of 1.0 per page. So the total PageRank on the web is equal to the number of pages on the web * 1, which equals a lot of PageRank spread around the web.
The Google toolbar range is from 1 to 10. (They sometimes show 0, but that figure isn't believed to be a PageRank calculation result). What Google does is divide the full range of actual PageRanks on the web into 10 parts - each part is represented by a value as shown in the toolbar. So the toolbar values only show what part of the overall range a page's PageRank is in, and not the actual PageRank itself. The numbers in the toolbar are just labels.
Whether or not the overall range is divided into 10 equal parts is a matter for debate - Google aren't saying. But because it is much harder to move up a toolbar point at the higher end than it is at the lower end, many people (including me) believe that the divisions are based on a logarithmic scale, or something very similar, rather than the equal divisions of a linear scale.
Let's assume that it is a logarithmic, base 10 scale, and that it takes 10 properly linked new pages to move a site's important page up 1 toolbar point. It will take 100 new pages to move it up another point, 1000 new pages to move it up one more, 10,000 to the next, and so on. That's why moving up at the lower end is much easier that at the higher end.
In reality, the base is unlikely to be 10. Some people think it is around the 5 or 6 mark, and maybe even less. Even so, it still gets progressively harder to move up a toolbar point at the higher end of the scale.
Note that as the number of pages on the web increases, so does the total PageRank on the web, and as the total PageRank increases, the positions of the divisions in the overall scale must change. As a result, some pages drop a toolbar point for no 'apparent' reason. If the page's actual PageRank was only just above a division in the scale, the addition of new pages to the web would cause the division to move up slightly and the page would end up just below the division. Google's index is always increasing and they re-evaluate each of the pages on more or less a monthly basis. It's known as the "Google dance". When the dance is over, some pages will have dropped a toolbar point. A number of new pages might be all that is needed to get the point back after the next dance.
The toolbar value is a good indicator of a page's PageRank but it only indicates that a page is in a certain range of the overall scale. One PR5 page could be just above the PR5 division and another PR5 page could be just below the PR6 division - almost a whole division (toolbar point) between them.
The Google toolbar range is from 1 to 10. (They sometimes show 0, but that figure isn't believed to be a PageRank calculation result). What Google does is divide the full range of actual PageRanks on the web into 10 parts - each part is represented by a value as shown in the toolbar. So the toolbar values only show what part of the overall range a page's PageRank is in, and not the actual PageRank itself. The numbers in the toolbar are just labels.
Whether or not the overall range is divided into 10 equal parts is a matter for debate - Google aren't saying. But because it is much harder to move up a toolbar point at the higher end than it is at the lower end, many people (including me) believe that the divisions are based on a logarithmic scale, or something very similar, rather than the equal divisions of a linear scale.
Let's assume that it is a logarithmic, base 10 scale, and that it takes 10 properly linked new pages to move a site's important page up 1 toolbar point. It will take 100 new pages to move it up another point, 1000 new pages to move it up one more, 10,000 to the next, and so on. That's why moving up at the lower end is much easier that at the higher end.
In reality, the base is unlikely to be 10. Some people think it is around the 5 or 6 mark, and maybe even less. Even so, it still gets progressively harder to move up a toolbar point at the higher end of the scale.
Note that as the number of pages on the web increases, so does the total PageRank on the web, and as the total PageRank increases, the positions of the divisions in the overall scale must change. As a result, some pages drop a toolbar point for no 'apparent' reason. If the page's actual PageRank was only just above a division in the scale, the addition of new pages to the web would cause the division to move up slightly and the page would end up just below the division. Google's index is always increasing and they re-evaluate each of the pages on more or less a monthly basis. It's known as the "Google dance". When the dance is over, some pages will have dropped a toolbar point. A number of new pages might be all that is needed to get the point back after the next dance.
The toolbar value is a good indicator of a page's PageRank but it only indicates that a page is in a certain range of the overall scale. One PR5 page could be just above the PR5 division and another PR5 page could be just below the PR6 division - almost a whole division (toolbar point) between them.
Outbound links PageRank Calculation
Outbound links are a drain on a site's total PageRank. They leak PageRank. To counter the drain, try to ensure that the links are reciprocated. Because of the PageRank of the pages at each end of an external link, and the number of links out from those pages, reciprocal links can gain or lose PageRank. You need to take care when choosing where to exchange links.
When PageRank leaks from a site via a link to another site, all the pages in the internal link structure are affected. (This doesn't always show after just 1 iteration). The page that you link out from makes a difference to which pages suffer the most loss. Without a program to perform the calculations on specific link structures, it is difficult to decide on the right page to link out from, but the generalization is to link from the one with the lowest PageRank.
Many websites need to contain some outbound links that are nothing to do with PageRank. Unfortunately, all 'normal' outbound links leak PageRank. But there are 'abnormal' ways of linking to other sites that don't result in leaks. PageRank is leaked when Google recognizes a link to another site. The answer is to use links that Google doesn't recognize or count. These include form actions and links contained in javascript code.
Form actions
A form's 'action' attribute does not need to be the url of a form parsing script. It can point to any html page on any site. Try it.
Example:
form_name="myform" action="http://www.domain.com/somepage.html">
a href="javascript:document.myform.submit()">Click here (/a>
To be really sneaky, the action attribute could be in some javascript code rather than in the form tag, and the javascript code could be loaded from a 'js' file stored in a directory that is barred to Google's spider by the robots.txt file.
Javascript
Example:
a href="javascript:goto('wherever')">Click here (/a>
Like the form action, it is sneaky to load the javascript code, which contains the urls, from a seperate 'js' file, and sneakier still if the file is stored in a directory that is barred to googlebot by the robots.txt file.
The "rel" attribute
As of 18th January 2005, Google, together with other search engines, is recognising a new attribute to the anchor tag. The attribute is "rel", and it is used as follows:-
a href="http://www.domain.com/somepage.html" rel="nofollow">link text (/a>
The attribute tells Google to ignore the link completely. The link won't help the target page's PageRank, and it won't help its rankings. It is as though the link doesn't exist. With this attribute, there is no longer any need for javascript, forms, or any other method of hiding links from Google.
When PageRank leaks from a site via a link to another site, all the pages in the internal link structure are affected. (This doesn't always show after just 1 iteration). The page that you link out from makes a difference to which pages suffer the most loss. Without a program to perform the calculations on specific link structures, it is difficult to decide on the right page to link out from, but the generalization is to link from the one with the lowest PageRank.
Many websites need to contain some outbound links that are nothing to do with PageRank. Unfortunately, all 'normal' outbound links leak PageRank. But there are 'abnormal' ways of linking to other sites that don't result in leaks. PageRank is leaked when Google recognizes a link to another site. The answer is to use links that Google doesn't recognize or count. These include form actions and links contained in javascript code.
Form actions
A form's 'action' attribute does not need to be the url of a form parsing script. It can point to any html page on any site. Try it.
Example:
form_name="myform" action="http://www.domain.com/somepage.html">
a href="javascript:document.myform.submit()">Click here (/a>
To be really sneaky, the action attribute could be in some javascript code rather than in the form tag, and the javascript code could be loaded from a 'js' file stored in a directory that is barred to Google's spider by the robots.txt file.
Javascript
Example:
a href="javascript:goto('wherever')">Click here (/a>
Like the form action, it is sneaky to load the javascript code, which contains the urls, from a seperate 'js' file, and sneakier still if the file is stored in a directory that is barred to googlebot by the robots.txt file.
The "rel" attribute
As of 18th January 2005, Google, together with other search engines, is recognising a new attribute to the anchor tag. The attribute is "rel", and it is used as follows:-
a href="http://www.domain.com/somepage.html" rel="nofollow">link text (/a>
The attribute tells Google to ignore the link completely. The link won't help the target page's PageRank, and it won't help its rankings. It is as though the link doesn't exist. With this attribute, there is no longer any need for javascript, forms, or any other method of hiding links from Google.
Inbound links PageRank Calculation
Inbound links (links into the site from the outside) are one way to increase a site's total PageRank. The other is to add more pages. Where the links come from doesn't matter. Google recognizes that a webmaster has no control over other sites linking into a site, and so sites are not penalized because of where the links come from. There is an exception to this rule but it is rare and doesn't concern this article. It isn't something that a webmaster can accidentally do.
The linking page's PageRank is important, but so is the number of links going from that page. For instance, if you are the only link from a page that has a lowly PR2, you will receive an injection of 0.15 + 0.85(2/1) = 1.85 into your site, whereas a link from a PR8 page that has another 99 links from it will increase your site's PageRank by 0.15 + 0.85(7/100) = 0.2095. Clearly, the PR2 link is much better - or is it?
Once the PageRank is injected into your site, the calculations are done again and each page's PageRank is changed. Depending on the internal link structure, some pages' PageRank is increased, some are unchanged but no pages lose any PageRank.
It is beneficial to have the inbound links coming to the pages to which you are channeling your PageRank. A PageRank injection to any other page will be spread around the site through the internal links. The important pages will receive an increase, but not as much of an increase as when they are linked to directly. The page that receives the inbound link, makes the biggest gain.
It is easy to think of our site as being a small, self-contained network of pages. When we do the PageRank calculations we are dealing with our small network. If we make a link to another site, we lose some of our network's PageRank, and if we receive a link, our network's PageRank is added to. But it isn't like that. For the PageRank calculations, there is only one network - every page that Google has in its index. Each iteration of the calculation is done on the entire network and not on individual websites.
Because the entire network is interlinked, and every link and every page plays its part in each iteration of the calculations, it is impossible for us to calculate the effect of inbound links to our site with any realistic accuracy.
The linking page's PageRank is important, but so is the number of links going from that page. For instance, if you are the only link from a page that has a lowly PR2, you will receive an injection of 0.15 + 0.85(2/1) = 1.85 into your site, whereas a link from a PR8 page that has another 99 links from it will increase your site's PageRank by 0.15 + 0.85(7/100) = 0.2095. Clearly, the PR2 link is much better - or is it?
Once the PageRank is injected into your site, the calculations are done again and each page's PageRank is changed. Depending on the internal link structure, some pages' PageRank is increased, some are unchanged but no pages lose any PageRank.
It is beneficial to have the inbound links coming to the pages to which you are channeling your PageRank. A PageRank injection to any other page will be spread around the site through the internal links. The important pages will receive an increase, but not as much of an increase as when they are linked to directly. The page that receives the inbound link, makes the biggest gain.
It is easy to think of our site as being a small, self-contained network of pages. When we do the PageRank calculations we are dealing with our small network. If we make a link to another site, we lose some of our network's PageRank, and if we receive a link, our network's PageRank is added to. But it isn't like that. For the PageRank calculations, there is only one network - every page that Google has in its index. Each iteration of the calculation is done on the entire network and not on individual websites.
Because the entire network is interlinked, and every link and every page plays its part in each iteration of the calculations, it is impossible for us to calculate the effect of inbound links to our site with any realistic accuracy.
Internal linking
Fact: A website has a maximum amount of PageRank that is distributed between its pages by internal links.
The maximum PageRank in a site equals the number of pages in the site * 1. The maximum is increased by inbound links from other sites and decreased by outbound links to other sites. We are talking about the overall PageRank in the site and not the PageRank of any individual page. You don't have to take my word for it. You can reach the same conclusion by using a pencil and paper and the equation.
Fact: The maximum amount of PageRank in a site increases as the number of pages in the site increases.
The more pages that a site has, the more PageRank it has. Again, by using a pencil and paper and the equation, you can come to the same conclusion. Bear in mind that the only pages that count are the ones that Google knows about.
Fact: By linking poorly, it is possible to fail to reach the site's maximum PageRank, but it is not possible to exceed it.
Poor internal linkages can cause a site to fall short of its maximum but no kind of internal link structure can cause a site to exceed it. The only way to increase the maximum is to add more inbound links and/or increase the number of pages in the site.
Cautions: Whilst I thoroughly recommend creating and adding new pages to increase a site's total PageRank so that it can be channeled to specific pages, there are certain types of pages that should not be added. These are pages that are all identical or very nearly identical and are known as cookie-cutters. Google considers them to be spam and they can trigger an alarm that causes the pages, and possibly the entire site, to be penalized. Pages full of good content are a must.
What can we do with this 'overall' PageRank?
We are going to look at some example calculations to see how a site's PageRank can be manipulated, but before doing that, I need to point out that a page will be included in the Google index only if one or more pages on the web link to it. That's according to Google. If a page is not in the Google index, any links from it can't be included in the calculations.
For the examples, we are going to ignore that fact, mainly because other 'Pagerank Explained' type documents ignore it in the calculations, and it might be confusing when comparing documents. The calculator operates in two modes:- Simple and Real. In Simple mode, the calculations assume that all pages are in the Google index, whether or not any other pages link to them. In Real mode the calculations disregard unlinked-to pages. These examples show the results as calculated in Simple mode. pagerank, page rank
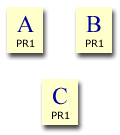
Let's consider a 3 page site (pages A, B and C) with no links coming in from the outside. We will allocate each page an initial PageRank of 1, although it makes no difference whether we start each page with 1, 0 or 99. Apart from a few millionths of a PageRank point, after many iterations the end result is always the same. Starting with 1 requires fewer iterations for the PageRanks to converge to a suitable result than when starting with 0 or any other number. You may want to use a pencil and paper to follow this or you can follow it with the calculator.
The site's maximum PageRank is the amount of PageRank in the site. In this case, we have 3 pages so the site's maximum is 3.
At the moment, none of the pages link to any other pages and none link to them. If you make the calculation once for each page, you'll find that each of them ends up with a PageRank of 0.15. No matter how many iterations you run, each page's PageRank remains at 0.15. The total PageRank in the site = 0.45, whereas it could be 3. The site is seriously wasting most of its potential PageRank.
__________________________________________
Example 1
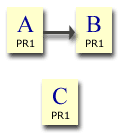
Now begin again with each page being allocated PR1. Link page A to page B and run the calculations for each page. We end up with:-
Page A = 0.15
Page B = 1
Page C = 0.15
Page A has "voted" for page B and, as a result, page B's PageRank has increased. This is looking good for page B, but it's only 1 iteration - we haven't taken account of the Catch 22 situation. Look at what happens to the figures after more iterations:-
After 100 iterations the figures are:-
Page A = 0.15
Page B = 0.2775
Page C = 0.15
It still looks good for page B but nowhere near as good as it did. These figures are more realistic. The total PageRank in the site is now 0.5775 - slightly better but still only a fraction of what it could be.
NOTE:
Technically, these particular results are incorrect because of the special treatment that Google gives to dangling links, but they serve to demonstrate the simple calculation.
_________________________________________________
Example 2
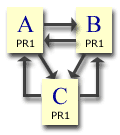
Try this linkage. Link all pages to all pages. Each page starts with PR1 again. This produces.
Page A = 1
Page B = 1
Page C = 1
Now we've achieved the maximum. No matter how many iterations are run, each page always ends up with PR1. The same results occur by linking in a loop. E.g. A to B, B to C and C to D. View this in the calculator.
This has demonstrated that, by poor linking, it is quite easy to waste PageRank and by good linking, we can achieve a site's full potential. But we don't particularly want all the site's pages to have an equal share. We want one or more pages to have a larger share at the expense of others. The kinds of pages that we might want to have the larger shares are the index page, hub pages and pages that are optimized for certain search terms. We have only 3 pages, so we'll channel the PageRank to the index page - page A. It will serve to show the idea of channeling.
________________________________________________
Example 3

Now try this. Link page A to both B and C. Also link pages B and C to A. Starting with PR1 all round, after 1 iteration the results are:-
Page A = 1.85
Page B = 0.575
Page C = 0.575
and after 100 iterations, the results are:-
Page A = 1.459459
Page B = 0.7702703
Page C = 0.7702703
In both cases the total PageRank in the site is 3 (the maximum) so none is being wasted. Also in both cases you can see that page A has a much larger proportion of the PageRank than the other 2 pages. This is because pages B and C are passing PageRank to A and not to any other pages. We have channeled a large proportion of the site's PageRank to where we wanted it.
________________________________________________
Example 4
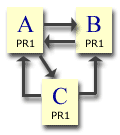
Finally, keep the previous links and add a link from page C to page B. Start again with PR1 all round. After 1 iteration:-
Page A = 1.425
Page B = 1
Page C = 0.575
By comparison to the 1 iteration figures in the previous example, page A has lost some PageRank, page B has gained some and page C stayed the same. Page C now shares its "vote" between A and B. Previously A received all of it. That's why page A has lost out and why page B has gained. and after 100 iterations:-
Page A = 1.298245
Page B = 0.9999999
Page C = 0.7017543
When the dust has settled, page C has lost a little PageRank because, having now shared its vote between A and B, instead of giving it all to A, A has less to give to C in the A-->C link. So adding an extra link from a page causes the page to lose PageRank indirectly if any of the pages that it links to return the link. If the pages that it links to don't return the link, then no PageRank loss would have occured. To make it more complicated, if the link is returned even indirectly (via a page that links to a page that links to a page etc), the page will lose a little PageRank. This isn't really important with internal links, but it does matter when linking to pages outside the site.
________________________________________________
Example 5: new pages
Adding new pages to a site is an important way of increasing a site's total PageRank because each new page will add an average of 1 to the total. Once the new pages have been added, their new PageRank can be channeled to the important pages. We'll use the calculator to demonstrate these.
Let's add 3 new pages to Example 3 [view]. Three new pages but they don't do anything for us yet. The small increase in the Total, and the new pages' 0.15, are unrealistic as we shall see. So let's link them into the site.
Link each of the new pages to the important page, page A [view]. Notice that the Total PageRank has doubled, from 3 (without the new pages) to 6. Notice also that page A's PageRank has almost doubled.
There is one thing wrong with this model. The new pages are orphans. They wouldn't get into Google's index, so they wouldn't add any PageRank to the site and they wouldn't pass any PageRank to page A. They each need to be linked to from at least one other page. If page A is the important page, the best page to put the links on is, surprisingly, page A [view]. You can play around with the links but, from page A's point of view, there isn't a better place for them.
It is not a good idea for one page to link to a large number of pages so, if you are adding many new pages, spread the links around. The chances are that there is more than one important page in a site, so it is usually suitable to spread the links to and from the new pages. You can use the calculator to experiment with mini-models of a site to find the best links that produce the best results for its important pages.
________________________________________________
Examples summary
You can see that, by organising the internal links, it is possible to channel a site's PageRank to selected pages. Internal links can be arranged to suit a site's PageRank needs, but it is only useful if Google knows about the pages, so do try to ensure that Google spiders them.
________________________________________________
Inbound and Outbound links
Examples of these could be given but it is probably clearer to read about them (below) and to 'play' with them in the calculator.
________________________________________________
Questions
When a page has several links to another page, are all the links counted?
E.g. if page A links once to page B and 3 times to page C, does page C receive 3/4 of page A's shareable PageRank?
The PageRank concept is that a page casts votes for one or more other pages. Nothing is said in the original PageRank document about a page casting more than one vote for a single page. The idea seems to be against the PageRank concept and would certainly be open to manipulation by unrealistically proportioning votes for target pages. E.g. if an outbound link, or a link to an unimportant page, is necessary, add a bunch of links to an important page to minimize the effect.
Since we are unlikely to get a definitive answer from Google, it is reasonable to assume that a page can cast only one vote for another page, and that additional votes for the same page are not counted.
When a page links to itself, is the link counted?
Again, the concept is that pages cast votes for other pages. Nothing is said in the original document about pages casting votes for themselves. The idea seems to be against the concept and, also, it would be another way to manipulate the results. So, for those reasons, it is reasonable to assume that a page can't vote for itself, and that such links are not counted.
Google's PageRank Explained and how to make the most of it... by Phil Craven
What is PageRank?
PageRank is a numeric value that represents how important a page is on the web. Google figures that when one page links to another page, it is effectively casting a vote for the other page. The more votes that are cast for a page, the more important the page must be. Also, the importance of the page that is casting the vote determines how important the vote itself is. Google calculates a page's importance from the votes cast for it. How important each vote is is taken into account when a page's PageRank is calculated.
PageRank is Google's way of deciding a page's importance. It matters because it is one of the factors that determines a page's ranking in the search results. It isn't the only factor that Google uses to rank pages, but it is an important one.
From here on in, we'll occasionally refer to PageRank as "PR".
Notes:
Not all links are counted by Google. For instance, they filter out links from known link farms. Some links can cause a site to be penalized by Google. They rightly figure that webmasters cannot control which sites link to their sites, but they can control which sites they link out to. For this reason, links into a site cannot harm the site, but links from a site can be harmful if they link to penalized sites. So be careful which sites you link to. If a site has PR0, it is usually a penalty, and it would be unwise to link to it.
How is PageRank calculated?
To calculate the PageRank for a page, all of its inbound links are taken into account. These are links from within the site and links from outside the site.
PR(A) = (1-d) + d(PR(t1)/C(t1) + ... + PR(tn)/C(tn))
That's the equation that calculates a page's PageRank. It's the original one that was published when PageRank was being developed, and it is probable that Google uses a variation of it but they aren't telling us what it is. It doesn't matter though, as this equation is good enough.
In the equation 't1 - tn' are pages linking to page A, 'C' is the number of outbound links that a page has and 'd' is a damping factor, usually set to 0.85.
We can think of it in a simpler way:-
a page's PageRank = 0.15 + 0.85 * (a "share" of the PageRank of every page that links to it)
"share" = the linking page's PageRank divided by the number of outbound links on the page.
A page "votes" an amount of PageRank onto each page that it links to. The amount of PageRank that it has to vote with is a little less than its own PageRank value (its own value * 0.85). This value is shared equally between all the pages that it links to.
From this, we could conclude that a link from a page with PR4 and 5 outbound links is worth more than a link from a page with PR8 and 100 outbound links. The PageRank of a page that links to yours is important but the number of links on that page is also important. The more links there are on a page, the less PageRank value your page will receive from it.
If the PageRank value differences between PR1, PR2,.....PR10 were equal then that conclusion would hold up, but many people believe that the values between PR1 and PR10 (the maximum) are set on a logarithmic scale, and there is very good reason for believing it. Nobody outside Google knows for sure one way or the other, but the chances are high that the scale is logarithmic, or similar. If so, it means that it takes a lot more additional PageRank for a page to move up to the next PageRank level that it did to move up from the previous PageRank level. The result is that it reverses the previous conclusion, so that a link from a PR8 page that has lots of outbound links is worth more than a link from a PR4 page that has only a few outbound links.
Whichever scale Google uses, we can be sure of one thing. A link from another site increases our site's PageRank. Just remember to avoid links from link farms.
Note that when a page votes its PageRank value to other pages, its own PageRank is not reduced by the value that it is voting. The page doing the voting doesn't give away its PageRank and end up with nothing. It isn't a transfer of PageRank. It is simply a vote according to the page's PageRank value. It's like a shareholders meeting where each shareholder votes according to the number of shares held, but the shares themselves aren't given away. Even so, pages do lose some PageRank indirectly, as we'll see later.
Ok so far? Good. Now we'll look at how the calculations are actually done.
For a page's calculation, its existing PageRank (if it has any) is abandoned completely and a fresh calculation is done where the page relies solely on the PageRank "voted" for it by its current inbound links, which may have changed since the last time the page's PageRank was calculated.
The equation shows clearly how a page's PageRank is arrived at. But what isn't immediately obvious is that it can't work if the calculation is done just once. Suppose we have 2 pages, A and B, which link to each other, and neither have any other links of any kind. This is what happens:-
Step 1: Calculate page A's PageRank from the value of its inbound links
Page A now has a new PageRank value. The calculation used the value of the inbound link from page B. But page B has an inbound link (from page A) and its new PageRank value hasn't been worked out yet, so page A's new PageRank value is based on inaccurate data and can't be accurate.
Step 2: Calculate page B's PageRank from the value of its inbound links
Page B now has a new PageRank value, but it can't be accurate because the calculation used the new PageRank value of the inbound link from page A, which is inaccurate.
It's a Catch 22 situation. We can't work out A's PageRank until we know B's PageRank, and we can't work out B's PageRank until we know A's PageRank.
Now that both pages have newly calculated PageRank values, can't we just run the calculations again to arrive at accurate values? No. We can run the calculations again using the new values and the results will be more accurate, but we will always be using inaccurate values for the calculations, so the results will always be inaccurate.
The problem is overcome by repeating the calculations many times. Each time produces slightly more accurate values. In fact, total accuracy can never be achieved because the calculations are always based on inaccurate values. 40 to 50 iterations are sufficient to reach a point where any further iterations wouldn't produce enough of a change to the values to matter. This is precisiely what Google does at each update, and it's the reason why the updates take so long.
One thing to bear in mind is that the results we get from the calculations are proportions. The figures must then be set against a scale (known only to Google) to arrive at each page's actual PageRank. Even so, we can use the calculations to channel the PageRank within a site around its pages so that certain pages receive a higher proportion of it than others.
NOTE:
You may come across explanations of PageRank where the same equation is stated but the result of each iteration of the calculation is added to the page's existing PageRank. The new value (result + existing PageRank) is then used when sharing PageRank with other pages. These explanations are wrong for the following reasons:-
1. They quote the same, published equation - but then change it
from PR(A) = (1-d) + d(......) to PR(A) = PR(A) + (1-d) + d(......)
It isn't correct, and it isn't necessary.
2. We will be looking at how to organize links so that certain pages end up with a larger proportion of the PageRank than others. Adding to the page's existing PageRank through the iterations produces different proportions than when the equation is used as published. Since the addition is not a part of the published equation, the results are wrong and the proportioning isn't accurate.
According to the published equation, the page being calculated starts from scratch at each iteration. It relies solely on its inbound links. The 'add to the existing PageRank' idea doesn't do that, so its results are necessarily wrong.
PageRank is a numeric value that represents how important a page is on the web. Google figures that when one page links to another page, it is effectively casting a vote for the other page. The more votes that are cast for a page, the more important the page must be. Also, the importance of the page that is casting the vote determines how important the vote itself is. Google calculates a page's importance from the votes cast for it. How important each vote is is taken into account when a page's PageRank is calculated.
PageRank is Google's way of deciding a page's importance. It matters because it is one of the factors that determines a page's ranking in the search results. It isn't the only factor that Google uses to rank pages, but it is an important one.
From here on in, we'll occasionally refer to PageRank as "PR".
Notes:
Not all links are counted by Google. For instance, they filter out links from known link farms. Some links can cause a site to be penalized by Google. They rightly figure that webmasters cannot control which sites link to their sites, but they can control which sites they link out to. For this reason, links into a site cannot harm the site, but links from a site can be harmful if they link to penalized sites. So be careful which sites you link to. If a site has PR0, it is usually a penalty, and it would be unwise to link to it.
How is PageRank calculated?
To calculate the PageRank for a page, all of its inbound links are taken into account. These are links from within the site and links from outside the site.
PR(A) = (1-d) + d(PR(t1)/C(t1) + ... + PR(tn)/C(tn))
That's the equation that calculates a page's PageRank. It's the original one that was published when PageRank was being developed, and it is probable that Google uses a variation of it but they aren't telling us what it is. It doesn't matter though, as this equation is good enough.
In the equation 't1 - tn' are pages linking to page A, 'C' is the number of outbound links that a page has and 'd' is a damping factor, usually set to 0.85.
We can think of it in a simpler way:-
a page's PageRank = 0.15 + 0.85 * (a "share" of the PageRank of every page that links to it)
"share" = the linking page's PageRank divided by the number of outbound links on the page.
A page "votes" an amount of PageRank onto each page that it links to. The amount of PageRank that it has to vote with is a little less than its own PageRank value (its own value * 0.85). This value is shared equally between all the pages that it links to.
From this, we could conclude that a link from a page with PR4 and 5 outbound links is worth more than a link from a page with PR8 and 100 outbound links. The PageRank of a page that links to yours is important but the number of links on that page is also important. The more links there are on a page, the less PageRank value your page will receive from it.
If the PageRank value differences between PR1, PR2,.....PR10 were equal then that conclusion would hold up, but many people believe that the values between PR1 and PR10 (the maximum) are set on a logarithmic scale, and there is very good reason for believing it. Nobody outside Google knows for sure one way or the other, but the chances are high that the scale is logarithmic, or similar. If so, it means that it takes a lot more additional PageRank for a page to move up to the next PageRank level that it did to move up from the previous PageRank level. The result is that it reverses the previous conclusion, so that a link from a PR8 page that has lots of outbound links is worth more than a link from a PR4 page that has only a few outbound links.
Whichever scale Google uses, we can be sure of one thing. A link from another site increases our site's PageRank. Just remember to avoid links from link farms.
Note that when a page votes its PageRank value to other pages, its own PageRank is not reduced by the value that it is voting. The page doing the voting doesn't give away its PageRank and end up with nothing. It isn't a transfer of PageRank. It is simply a vote according to the page's PageRank value. It's like a shareholders meeting where each shareholder votes according to the number of shares held, but the shares themselves aren't given away. Even so, pages do lose some PageRank indirectly, as we'll see later.
Ok so far? Good. Now we'll look at how the calculations are actually done.
For a page's calculation, its existing PageRank (if it has any) is abandoned completely and a fresh calculation is done where the page relies solely on the PageRank "voted" for it by its current inbound links, which may have changed since the last time the page's PageRank was calculated.
The equation shows clearly how a page's PageRank is arrived at. But what isn't immediately obvious is that it can't work if the calculation is done just once. Suppose we have 2 pages, A and B, which link to each other, and neither have any other links of any kind. This is what happens:-
Step 1: Calculate page A's PageRank from the value of its inbound links
Page A now has a new PageRank value. The calculation used the value of the inbound link from page B. But page B has an inbound link (from page A) and its new PageRank value hasn't been worked out yet, so page A's new PageRank value is based on inaccurate data and can't be accurate.
Step 2: Calculate page B's PageRank from the value of its inbound links
Page B now has a new PageRank value, but it can't be accurate because the calculation used the new PageRank value of the inbound link from page A, which is inaccurate.
It's a Catch 22 situation. We can't work out A's PageRank until we know B's PageRank, and we can't work out B's PageRank until we know A's PageRank.
Now that both pages have newly calculated PageRank values, can't we just run the calculations again to arrive at accurate values? No. We can run the calculations again using the new values and the results will be more accurate, but we will always be using inaccurate values for the calculations, so the results will always be inaccurate.
The problem is overcome by repeating the calculations many times. Each time produces slightly more accurate values. In fact, total accuracy can never be achieved because the calculations are always based on inaccurate values. 40 to 50 iterations are sufficient to reach a point where any further iterations wouldn't produce enough of a change to the values to matter. This is precisiely what Google does at each update, and it's the reason why the updates take so long.
One thing to bear in mind is that the results we get from the calculations are proportions. The figures must then be set against a scale (known only to Google) to arrive at each page's actual PageRank. Even so, we can use the calculations to channel the PageRank within a site around its pages so that certain pages receive a higher proportion of it than others.
NOTE:
You may come across explanations of PageRank where the same equation is stated but the result of each iteration of the calculation is added to the page's existing PageRank. The new value (result + existing PageRank) is then used when sharing PageRank with other pages. These explanations are wrong for the following reasons:-
1. They quote the same, published equation - but then change it
from PR(A) = (1-d) + d(......) to PR(A) = PR(A) + (1-d) + d(......)
It isn't correct, and it isn't necessary.
2. We will be looking at how to organize links so that certain pages end up with a larger proportion of the PageRank than others. Adding to the page's existing PageRank through the iterations produces different proportions than when the equation is used as published. Since the addition is not a part of the published equation, the results are wrong and the proportioning isn't accurate.
According to the published equation, the page being calculated starts from scratch at each iteration. It relies solely on its inbound links. The 'add to the existing PageRank' idea doesn't do that, so its results are necessarily wrong.
Friday, August 04, 2006
SEO and URL Structure By Shari Thurow
One of the most hotly debated topics in the search industry is the importance of a Web page's URL structure (the Web address) for ranking purposes. Some SEO (define) experts feel placing keywords in the URL is vitally important; a Web page simply won't rank well without keywords in the URL. This group often cites SERPs (define) with keywords highlighted as hard evidence for its viewpoint.
On the flip side, other SEO experts believe keywords in the URL don't make or break search engine positions. Yet this group recognizes how important keywords are from a usability perspective: both search engines' and site visitors'. This group doesn't give much emphasis to keyword-rich URLs for determining relevancy.
I wanted to explore this topic because how search engines handle the wide variety of URL structures is constantly evolving.
URL Structure as Interface
The people who least understand issues with URL structure and SEO are the very people who create them: Web developers, programmers, and software developers. It seems the most important item to them is getting the database to function without any consideration for the interface. Therein lies the problem. Too few IT and technical staff have any education, training, and experience in user-centered design (UCD).
After keyword research, the first component in creating a Web site is to come up with the site's information architecture. Remember, information architecture and interface are two different things. How information is grouped on a Web page and overall on a Web site is information architecture. One way to remember this is information architecture equals grouping and categorization.
In other words, information architecture is how a Web site's information is organized. Before anyone creates interface prototypes, information architecture must be determined. If interface designers (often IT staff, to the detriment of the Web site) are brought in too early in the Web development and SEO process, the information architecture might be compromised.
After Web site owners determine how information should be categorized or grouped on a site, the interface talent should work on initial prototypes. Keywords, general Web copy, graphic images, multimedia files, and URL structure are all part of this interface. An effective interface communicates keyword focus to both search engines and site visitors. For this reason I classify Web site usability as an intermediate-level SEO skill, one that few advanced SEO professionals possess.
Dynamic URLs and SEO
It's pointless to optimize a Web page without giving search engines easy access to that page's content. Navigation schemes and URL structures often act as a stop sign to search engine indexing.
URL structure can be a confusing topic. For example, people tend to assume a dynamic URL contains funky characters (e.g., "?," "=," "&"), as in "http://www.site.com/products.asp?product_no=25," as opposed to "http://www.site.com/hikingboots.html."
At first glance, it might seem the first URL is dynamic and the second one is static. However, a static-looking URL can be database-driven, and the dynamic-looking URL can actually be a static URL.
In truth, search engines don't wish to crawl Web sites with too many parameters in the URL. Search engine software engineers have a considerable amount of search data. They recognize URL patterns that are potentially problematic. Content management systems often generate problematic URLs.
Additionally, search engines limit the number of characters they'll crawl in a URL. This is partially due to known problems in URL structures and partially to Web site usability. Go to any SERP. Look at URL structures. Which is easiest for you, the searcher, to remember? Static-looking, shorter URLs are usually the easiest to remember.
Information Architecture of the URL
Perhaps the most striking observation I've made in my years of training companies is how IT staff and Web developers ignore URL structure as an important element of a Web page's interface. The typical statement I hear is, "Our site is database-driven. We don't have an information architecture."
But a database-driven Web site still communicates information architecture to both search engines and end users through the interface.
I performed a search usability analysis on a large commerce site recently. The main problem with the site's interface was product pages were only made available through a site search engine. Immediately, I knew the site had problems with search engine visibility because the commercial Web search engines don't want search results in their search results. It's a bad user experience for searchers. Additionally, the URL structure has too many parameters, resulting in a large number of characters in the URL.
The result? Because this database-driven site practically orphaned important product pages through the URL structure, search engine spiders didn't access this content easily.
Even database-driven sites have an information architecture. For example, what does the following URL communicate: "http://www.site.com/videos/flash/2006/running.swf"?
You can immediately see you're looking at a Flash video file about running that was either created or posted in 2006. It looks like the site might have a video repository, and maybe it has other video file formats than Flash. What I just described is how information is organized -- an information architecture.
Conclusion
What does this have to do with SEO? If related items are grouped together and cross-linked well, keyword focus is communicated to search engines and site visitors. If the interface uses important keyword phrases in navigation labels, headings, URLs, and so forth (in other words, if the interface supports a site's information architecture), the interface also communicates keyword focus. A page's linkage properties also become more keyword focused.
A long time ago, I read on some black-hat Web site that one of the authors made a bold statement about "poor" white-hat SEO professionals. I have no idea why the author made the assumption that white-hat practices (such as Web site usability and search-friendly interface design) aren't a growing and profitable industry. Don't discount interface design as a part of the SEO process. Personally, I find it delivers the highest ROI (define) over time.
On the flip side, other SEO experts believe keywords in the URL don't make or break search engine positions. Yet this group recognizes how important keywords are from a usability perspective: both search engines' and site visitors'. This group doesn't give much emphasis to keyword-rich URLs for determining relevancy.
I wanted to explore this topic because how search engines handle the wide variety of URL structures is constantly evolving.
URL Structure as Interface
The people who least understand issues with URL structure and SEO are the very people who create them: Web developers, programmers, and software developers. It seems the most important item to them is getting the database to function without any consideration for the interface. Therein lies the problem. Too few IT and technical staff have any education, training, and experience in user-centered design (UCD).
After keyword research, the first component in creating a Web site is to come up with the site's information architecture. Remember, information architecture and interface are two different things. How information is grouped on a Web page and overall on a Web site is information architecture. One way to remember this is information architecture equals grouping and categorization.
In other words, information architecture is how a Web site's information is organized. Before anyone creates interface prototypes, information architecture must be determined. If interface designers (often IT staff, to the detriment of the Web site) are brought in too early in the Web development and SEO process, the information architecture might be compromised.
After Web site owners determine how information should be categorized or grouped on a site, the interface talent should work on initial prototypes. Keywords, general Web copy, graphic images, multimedia files, and URL structure are all part of this interface. An effective interface communicates keyword focus to both search engines and site visitors. For this reason I classify Web site usability as an intermediate-level SEO skill, one that few advanced SEO professionals possess.
Dynamic URLs and SEO
It's pointless to optimize a Web page without giving search engines easy access to that page's content. Navigation schemes and URL structures often act as a stop sign to search engine indexing.
URL structure can be a confusing topic. For example, people tend to assume a dynamic URL contains funky characters (e.g., "?," "=," "&"), as in "http://www.site.com/products.asp?product_no=25," as opposed to "http://www.site.com/hikingboots.html."
At first glance, it might seem the first URL is dynamic and the second one is static. However, a static-looking URL can be database-driven, and the dynamic-looking URL can actually be a static URL.
In truth, search engines don't wish to crawl Web sites with too many parameters in the URL. Search engine software engineers have a considerable amount of search data. They recognize URL patterns that are potentially problematic. Content management systems often generate problematic URLs.
Additionally, search engines limit the number of characters they'll crawl in a URL. This is partially due to known problems in URL structures and partially to Web site usability. Go to any SERP. Look at URL structures. Which is easiest for you, the searcher, to remember? Static-looking, shorter URLs are usually the easiest to remember.
Information Architecture of the URL
Perhaps the most striking observation I've made in my years of training companies is how IT staff and Web developers ignore URL structure as an important element of a Web page's interface. The typical statement I hear is, "Our site is database-driven. We don't have an information architecture."
But a database-driven Web site still communicates information architecture to both search engines and end users through the interface.
I performed a search usability analysis on a large commerce site recently. The main problem with the site's interface was product pages were only made available through a site search engine. Immediately, I knew the site had problems with search engine visibility because the commercial Web search engines don't want search results in their search results. It's a bad user experience for searchers. Additionally, the URL structure has too many parameters, resulting in a large number of characters in the URL.
The result? Because this database-driven site practically orphaned important product pages through the URL structure, search engine spiders didn't access this content easily.
Even database-driven sites have an information architecture. For example, what does the following URL communicate: "http://www.site.com/videos/flash/2006/running.swf"?
You can immediately see you're looking at a Flash video file about running that was either created or posted in 2006. It looks like the site might have a video repository, and maybe it has other video file formats than Flash. What I just described is how information is organized -- an information architecture.
Conclusion
What does this have to do with SEO? If related items are grouped together and cross-linked well, keyword focus is communicated to search engines and site visitors. If the interface uses important keyword phrases in navigation labels, headings, URLs, and so forth (in other words, if the interface supports a site's information architecture), the interface also communicates keyword focus. A page's linkage properties also become more keyword focused.
A long time ago, I read on some black-hat Web site that one of the authors made a bold statement about "poor" white-hat SEO professionals. I have no idea why the author made the assumption that white-hat practices (such as Web site usability and search-friendly interface design) aren't a growing and profitable industry. Don't discount interface design as a part of the SEO process. Personally, I find it delivers the highest ROI (define) over time.
Subscribe to:
Posts (Atom)